
I am currently working as a Machine Learning Scientist at Roctop. Previously, I worked on leveraging machine learning for agent-based modelling and mechanism design in the context
of biodiversity conservation as a postdoc advised by Profs. Clément Chion at UQO and James Wright at UofA and
Amii (Alberta Machine Intelligence Institute).
I have successfully defended my Ph.D. thesis Coordination in Cooperative Multi-Agent Learning at McGill
University and Mila (Quebec AI Institute) co-supervised by Prof. Derek Nowrouzezahrai and Prof. Christopher Pal.
I work on sequential decision-making, focusing on multi-agent problems such as the emergence of communication,
brain-computer interfaces, coordination, and cooperation challenges.
When available, I am keen to leverage data and simulators through model-based planning and learning; or
imitation, inverse, and offline reinforcement learning approaches.
My research goal is to leverage data-driven multi-agent sequential decision-making to model intricate systems
and assist us with complex decision processes.
I am particularly interested in applying agent-based modeling and mechanism design approaches to challenges
across governance, public health, and biodiversity conservation.
I have a multidisciplinary academic background and hold a B.Sc. and an M.Sc. in Mechanical Engineering from EPFL
(Swiss Federal Institute of Technology Lausanne) where I specialized in Fluid Dynamics and Computational Fluid
Simulation.
Jointly, I graduated from the Data and Decision Science program at ISAE-Supaero (National Higher French
Institute of Aeronautics and Space) with a minor in Robotics and Autonomous Systems.
At EPFL, I received the Excellence Scholarship for Master Studies and the Double Degree Swiss-European Mobility
Program Award.
In the recent past, I have worked at Ubisoft La Forge with Dr. Olivier Delalleau, at INRIA (National Institute
for Research in Digital Science and Technology) with Prof. Pierre-Yves Oudeyer, and most recently at FAIR (Meta
Fundamental AI Research) with Prof. Amy Zhang. During my Ph.D. I have been funded by Mitacs and I am currently supported by a NSERC Postdoctoral Fellowship (I have also been awarded a non cumulative FRQNT Postdoctoral Scholarship).
News
| December 2024 | I have started working at Roctop! 🎉 |
| April 2024 | I have been awarded a FRQNT Postdoctoral Scholarship! 🎉 |
| February 2024 | I have been awarded a NSERC Postdoctoral Fellowship! 🎉 |
| January 2024 | I am starting a postdoc with Clément Chion and James Wright to work on agent-based modelling in the context of biodiversity conservation! 🎉 |
| January 2024 | Our latest paper A Model-Based Solution to the Offline Multi-Agent Reinforcement Learning Coordination Problem has been accepted at AAMAS 2024! 🎉 |
| December 2023 | I have successfully defended my Ph.D. thesis "Coordination in Cooperative Multi-Agent Learning" and I will be graduating in February! 😁 |
Research
Selected Projects
For a complete list of my publications see my Scholar.

A
Model-Based Solution to the Offline Multi-Agent Reinforcement Learning Coordination Problem
AAMAS 2024
Website
Talk
Slides
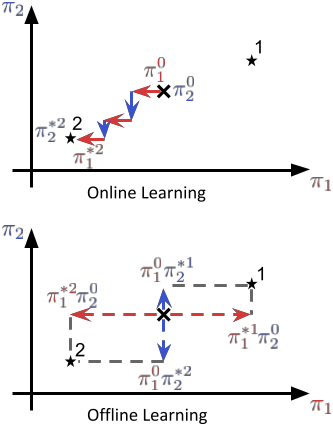
Current Offline MARL methods fail at what we identify as the offline coordination problem.
Specifically, methods struggle with strategy agreement and strategy fine-tuning. To address this setback,
we propose a simple model-based approach that generates synthetic interaction data and enables agents to
converge
on a strategy while fine-tuning their policies accordingly. Our resulting method outperforms the prevalent
learning
methods even under severe partial observability and with learned world models.
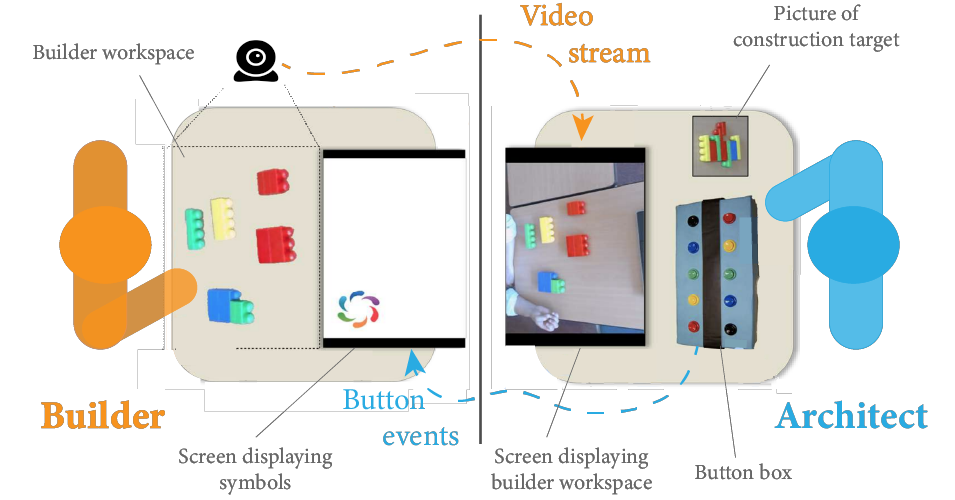
Learning to Guide and to Be Guided in the Architect-Builder Problem
ICLR 2022
Website
Code
Blog post
Talk
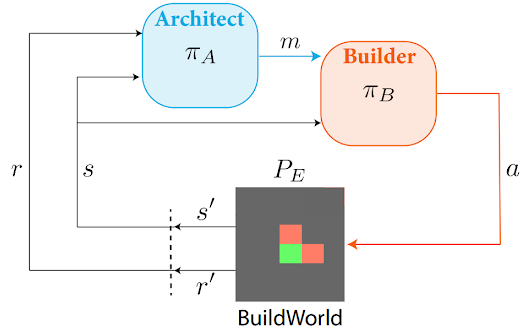
We proposed a novel learning setting to investigate the emergence of communication in a setting that can
model Brain-Computer Interfaces (e.g., a user controls a prosthetic
arm from brain signals).
In this learning paradigm, that we dub the Architect-Builder Problem, agents learn to coordinate in the
manner of a builder -- who performs actions but ignores the task --
and an architect who guides the builder towards the goal of the task but cannot directly act.

Adversarial Soft Advantage Fitting: Imitation Learning without Policy
Optimization
NeurIPS 2020 Spotlight
Code
Talk
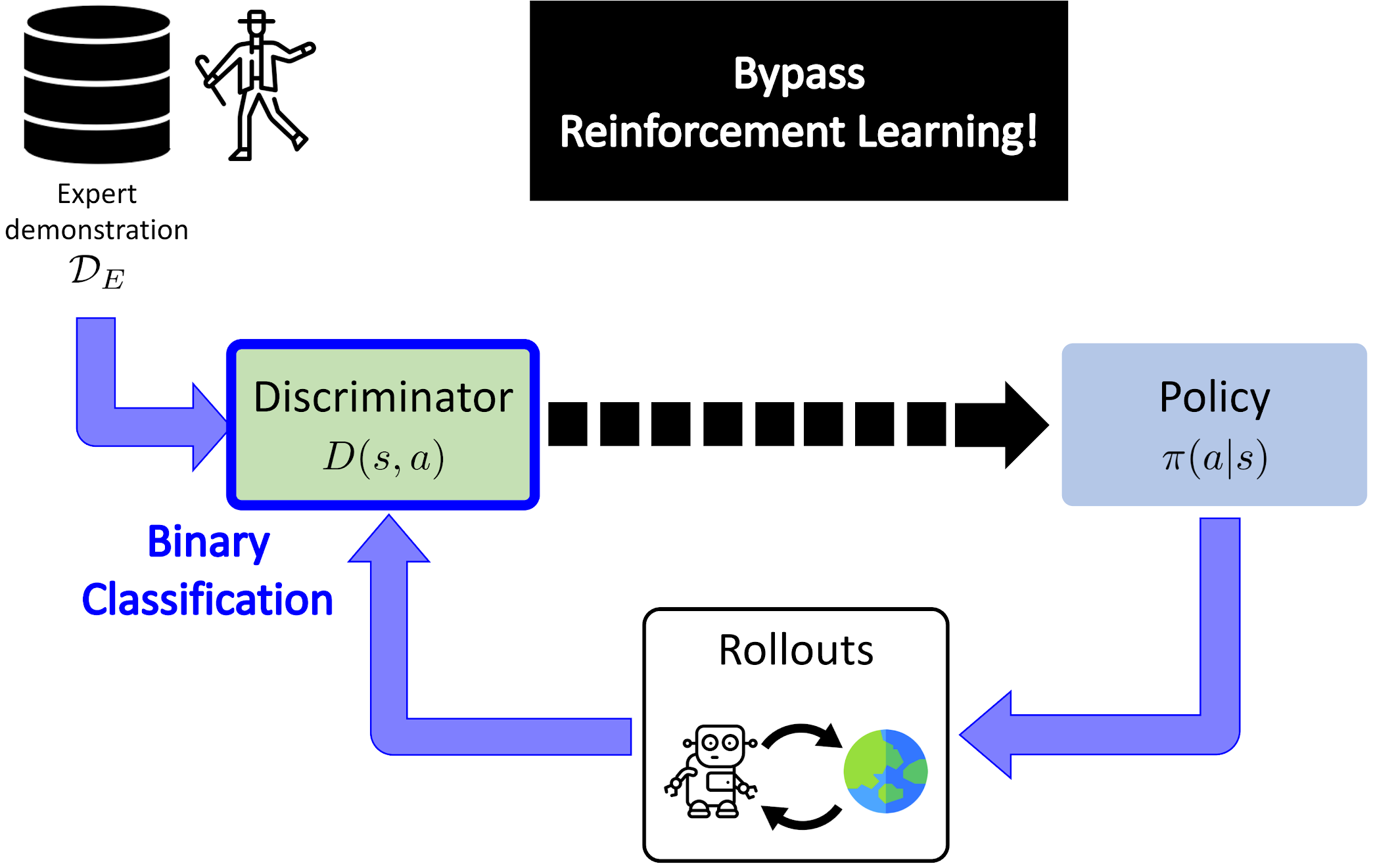
Current Adversarial Imitation Learning methods are prohibitively complicated which prevents their use for
multi-agent modeling.
We proposed to remove the Reinforcement Learning loop of current algorithms, greatly simplifying their
algorithmic complexity while improving performance and robustness.
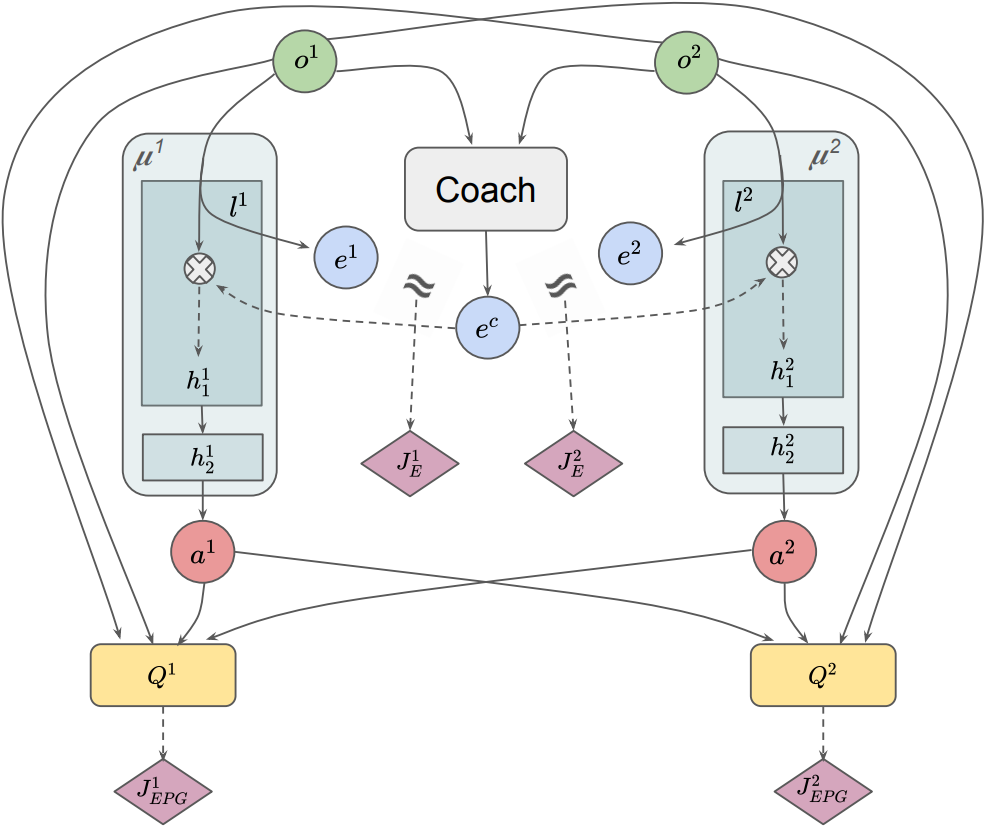

Promoting Coordination through Policy Regularization in Multi-Agent Deep
Reinforcement Learning
NeurIPS 2020
Code
Website
Talk
Current MARL methods fail in training agents that account for teammates’ behavior, and that is even when
agents have access to the observations and policies of the whole team. To palliate this,
we proposed to promote inter-agent coordination via inter-agent predictability and synchronous behavior
selection.
We showed how two inductive biases on the policy search can serve as proxies for such coordination and boost
performance in cooperative tasks.
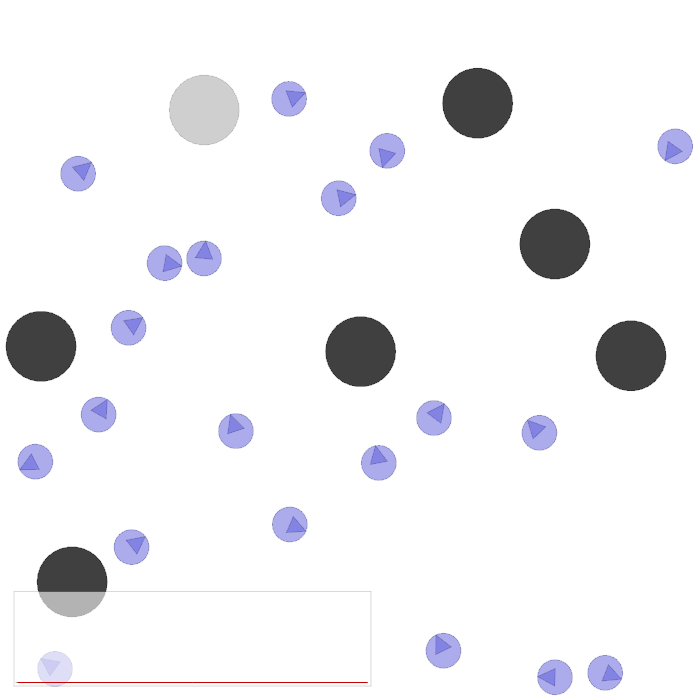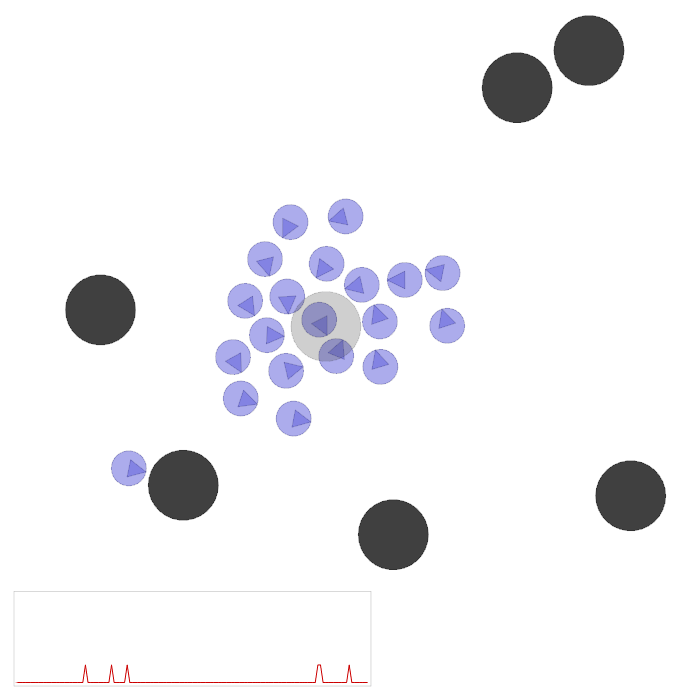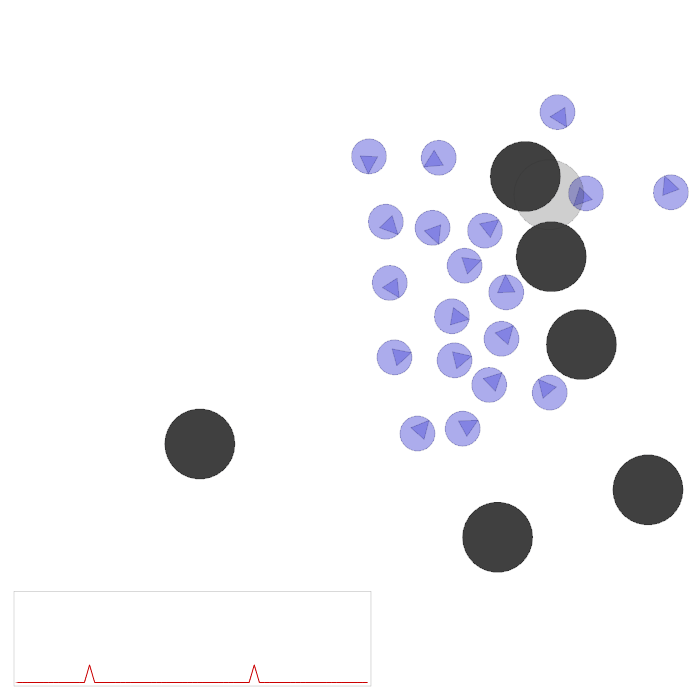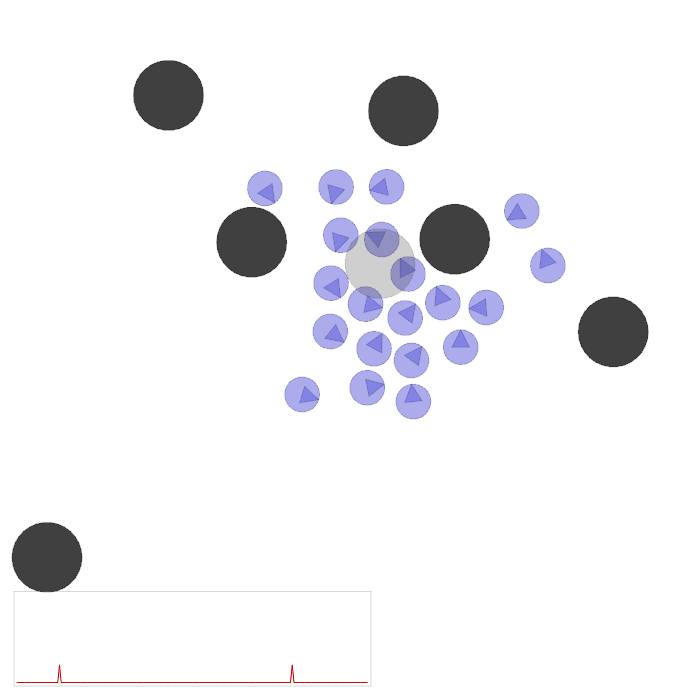
MARL for Many Agent Navigation and Swarm Simulation
Master project
Investigated Multi-Agent Reinforcement Learning methods with parameter sharing to achieve more organic
simulations with many agents.
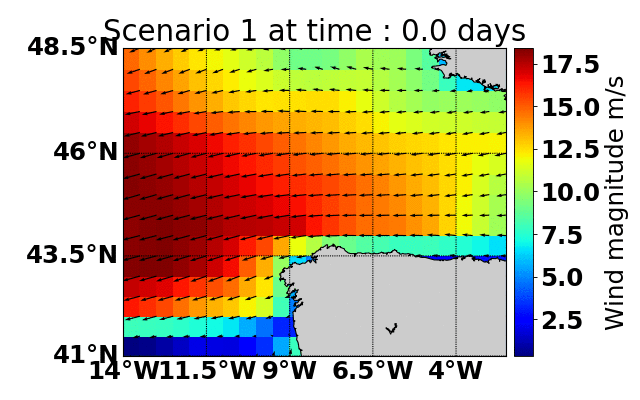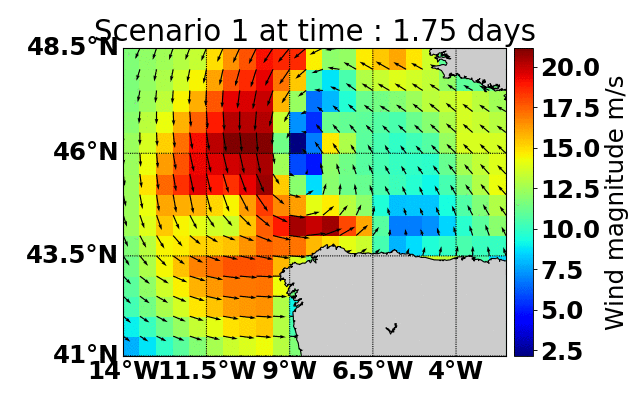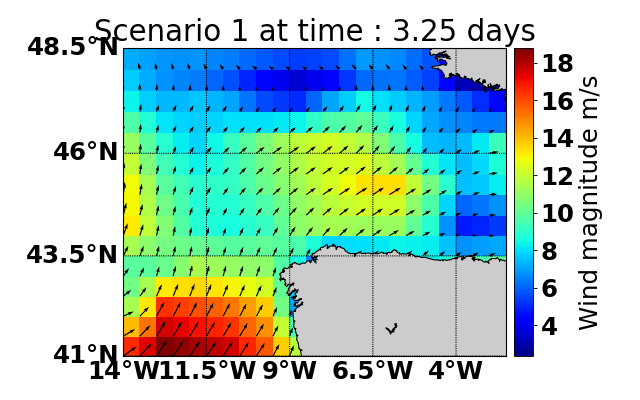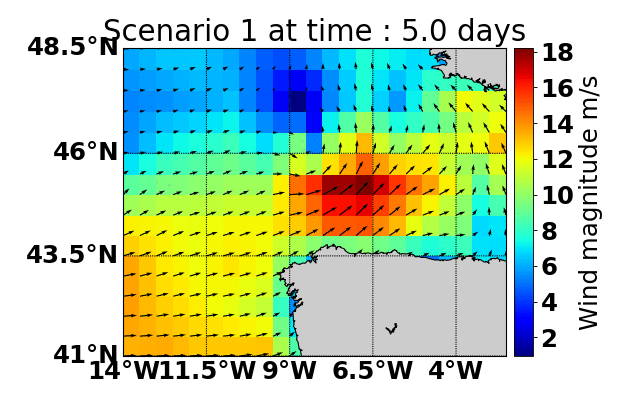
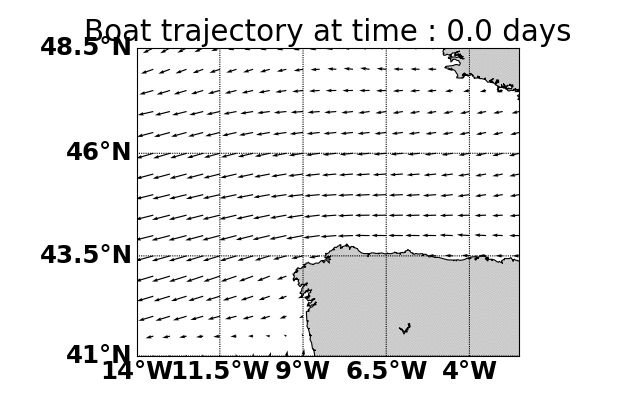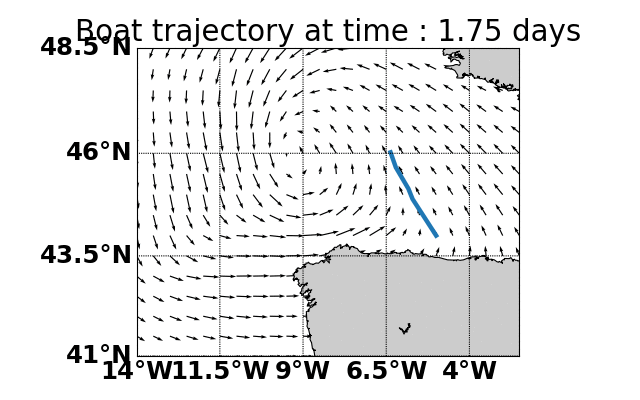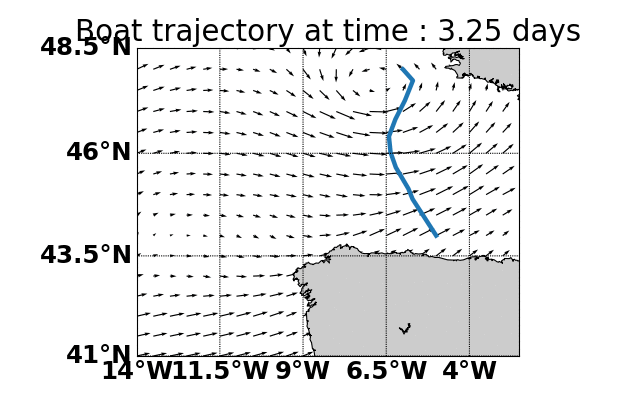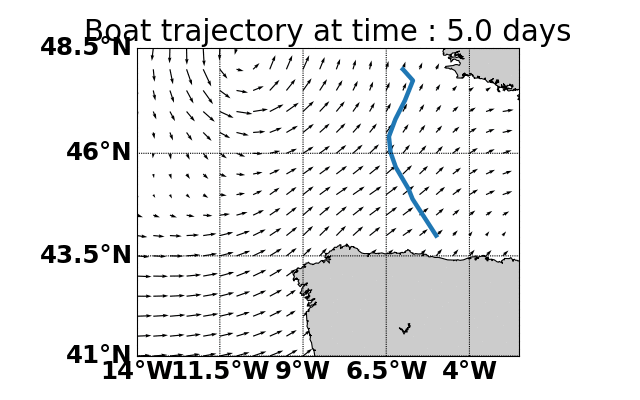
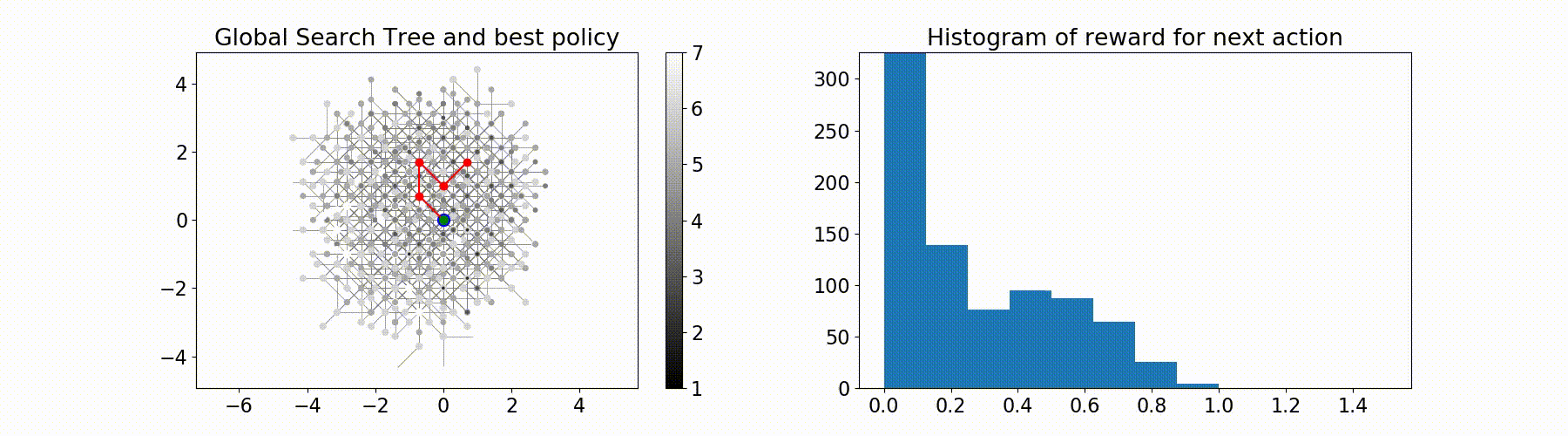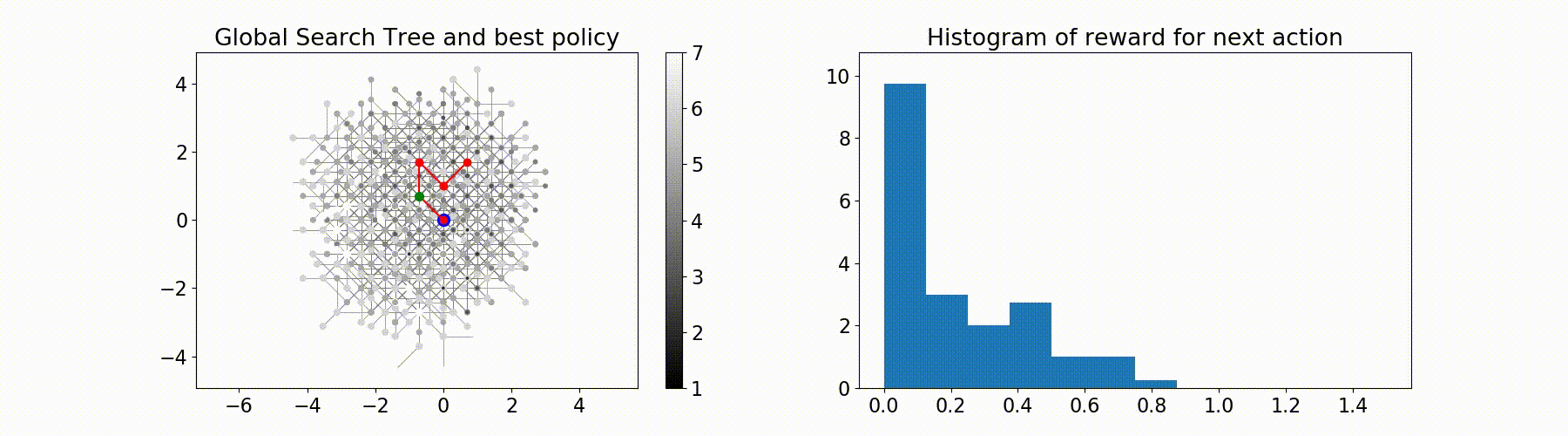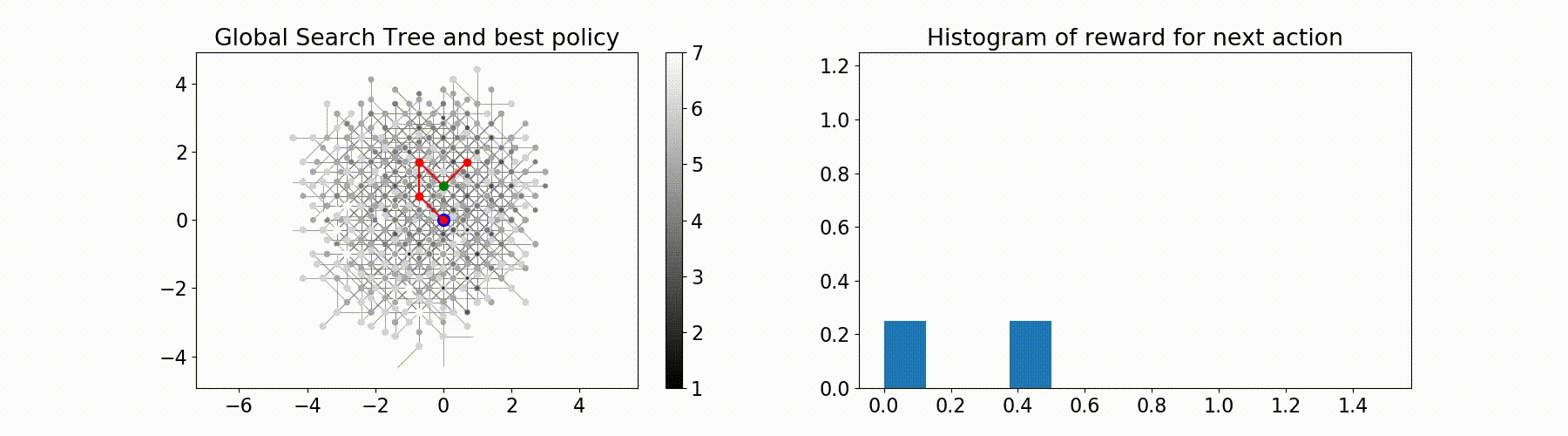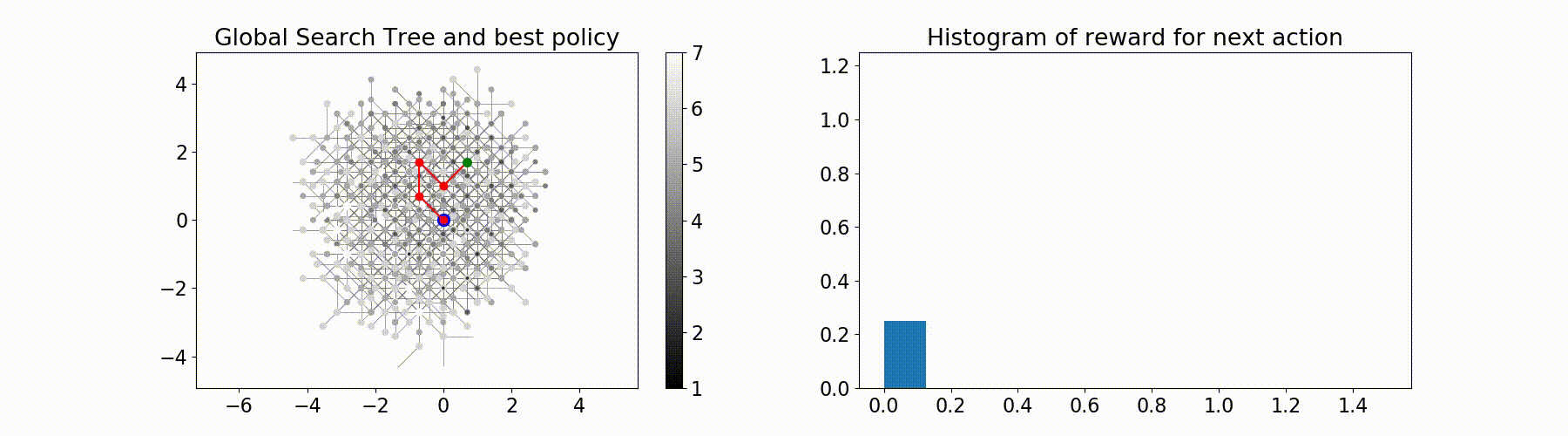
Parallel Monte-Carlo Tree Search for Path Planning under Multiple Weather Forecast
Scenarios for Autonomous Sailboat
Master
project
Code
Documentation
Technical
Brief
Draft Paper
Built a sailboat navigation simulator that automatically
downloaded multiple wind weather forecasts from the open-source Global Forecast System (GFS) model on NOAA
servers and applied a parallel version of MCTS planning
to compute the optimal sailing trajectory across the different weather scenarios.
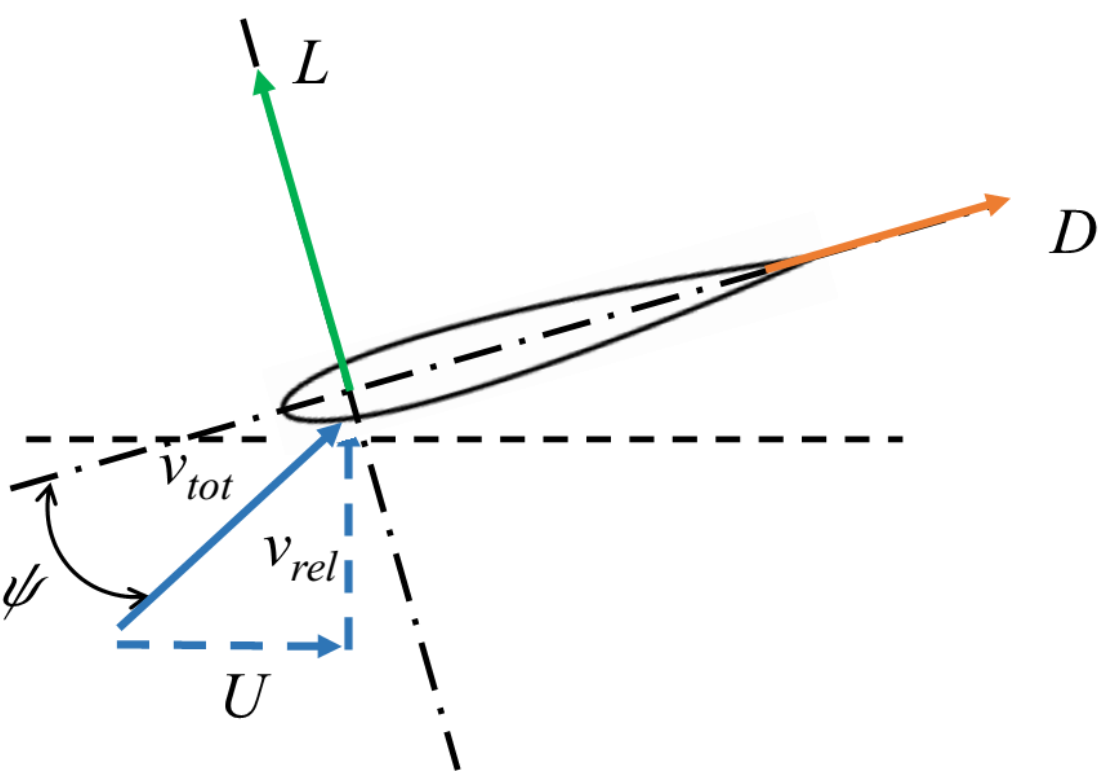

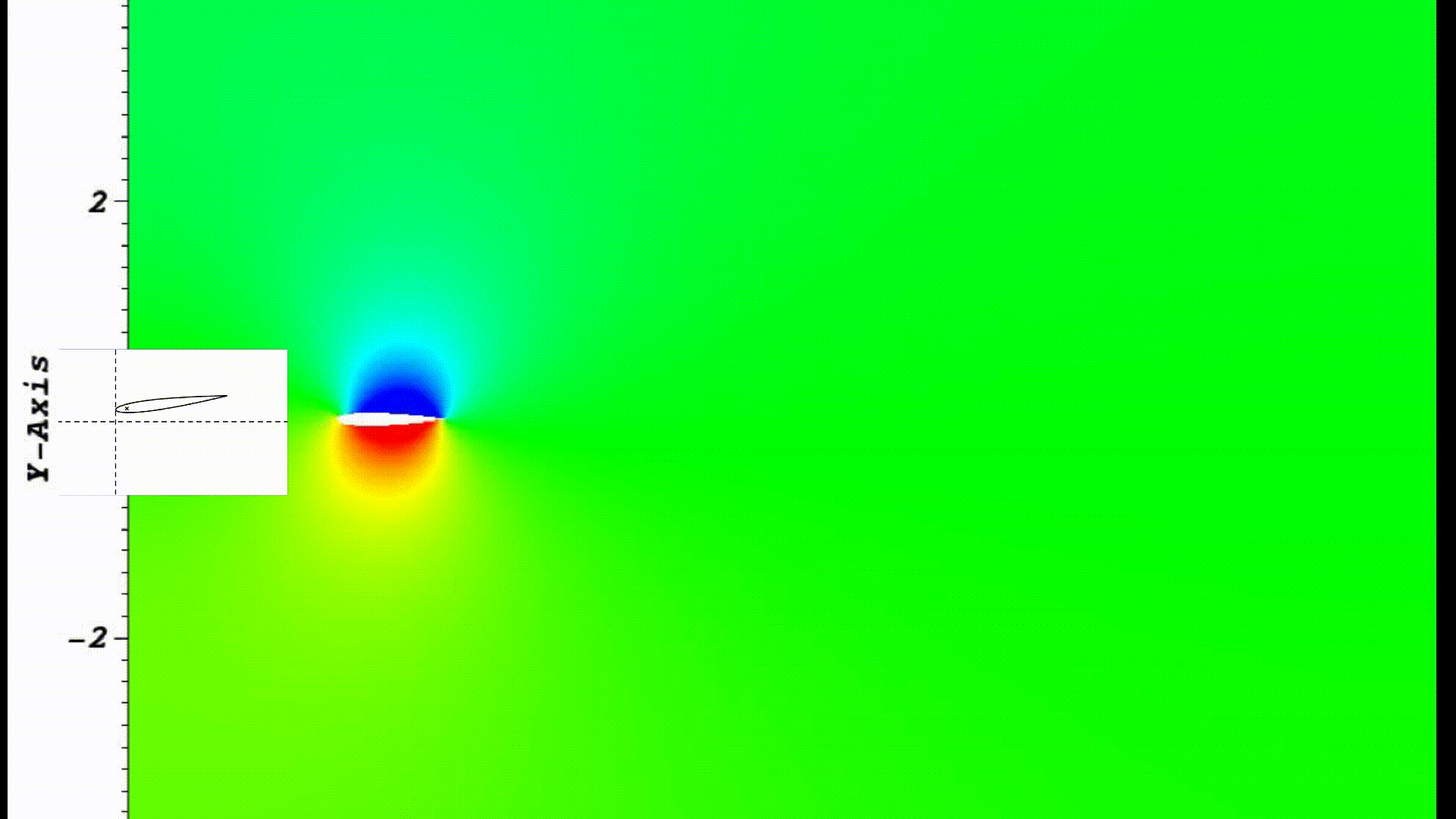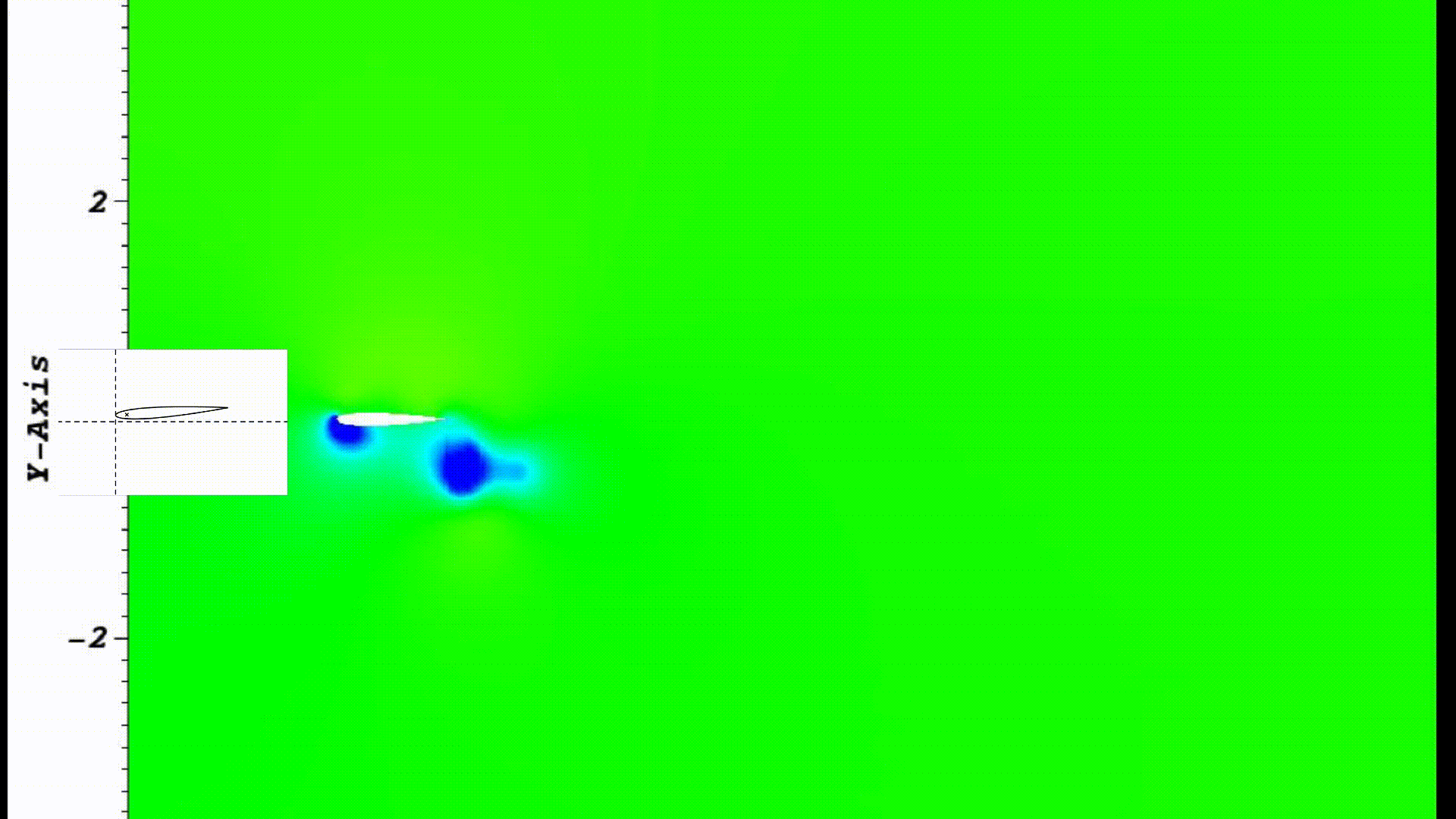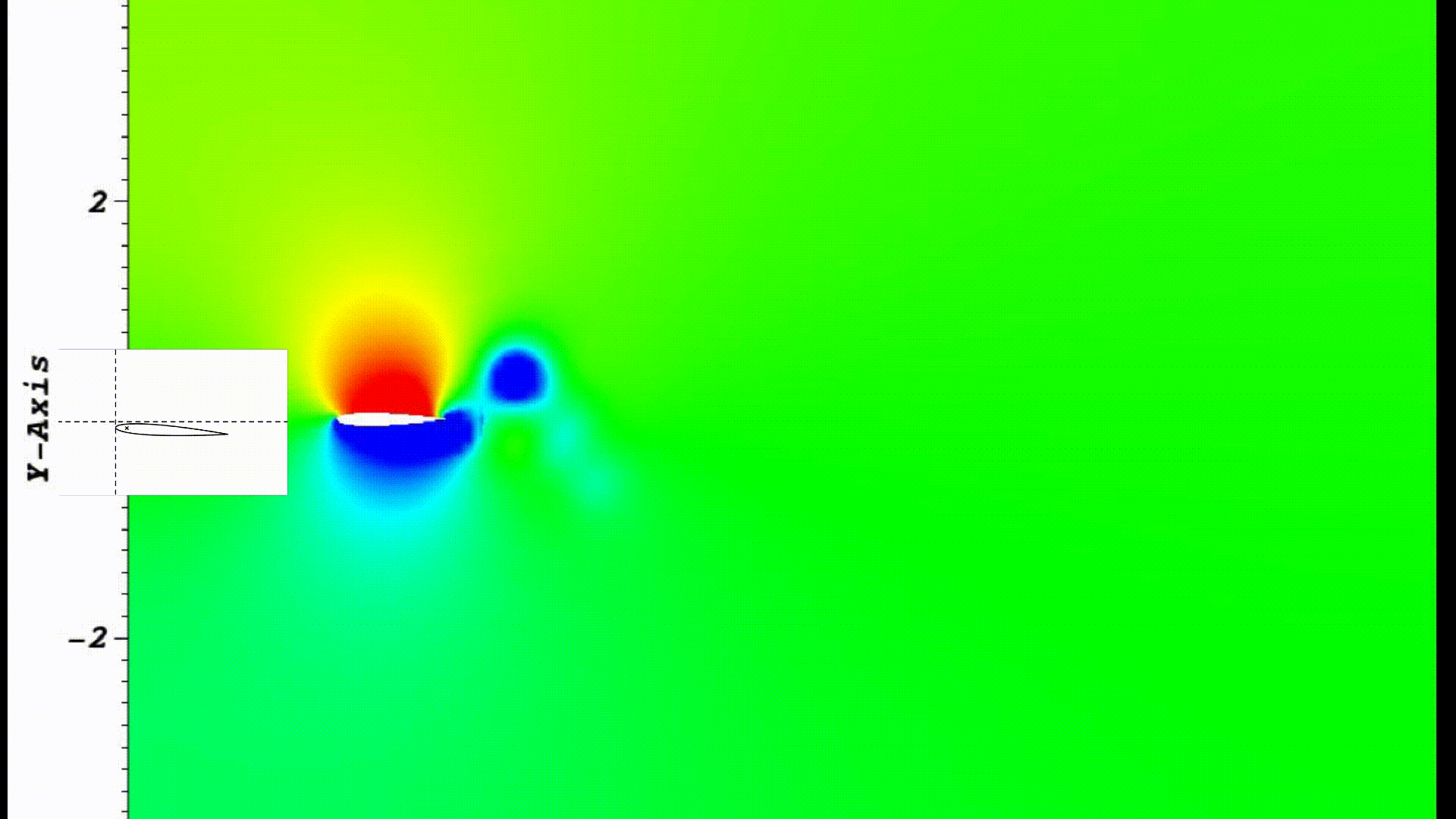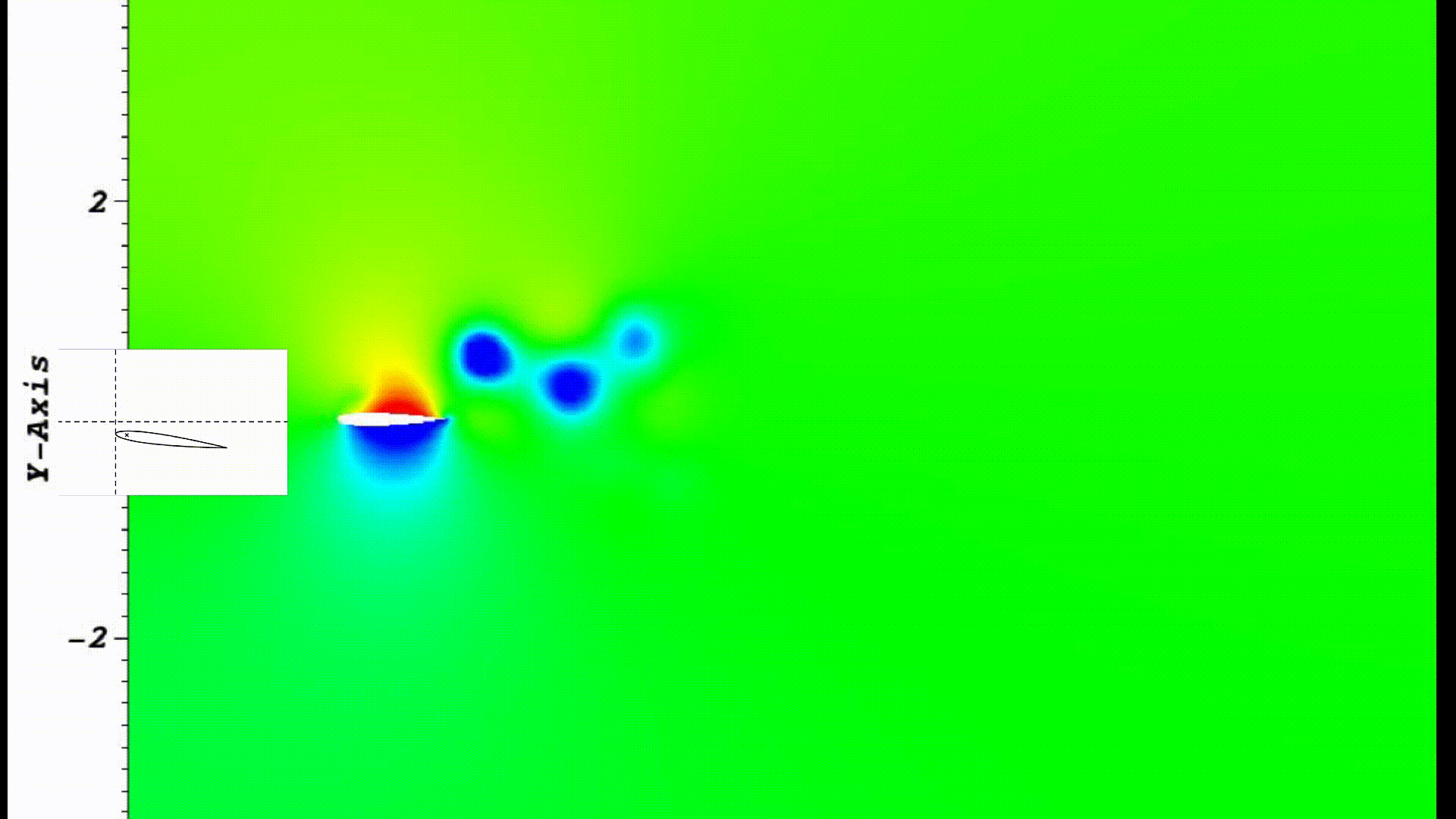
Optimal flapping and pitching motion of NACA airfoils for thrust generation
Master project
Report
Used numerical flow simulation to investigate how the combined flapping and pitching motions of an airfoil
profile can result in forward thrust generation (i.e. sea turtles like locomotion).

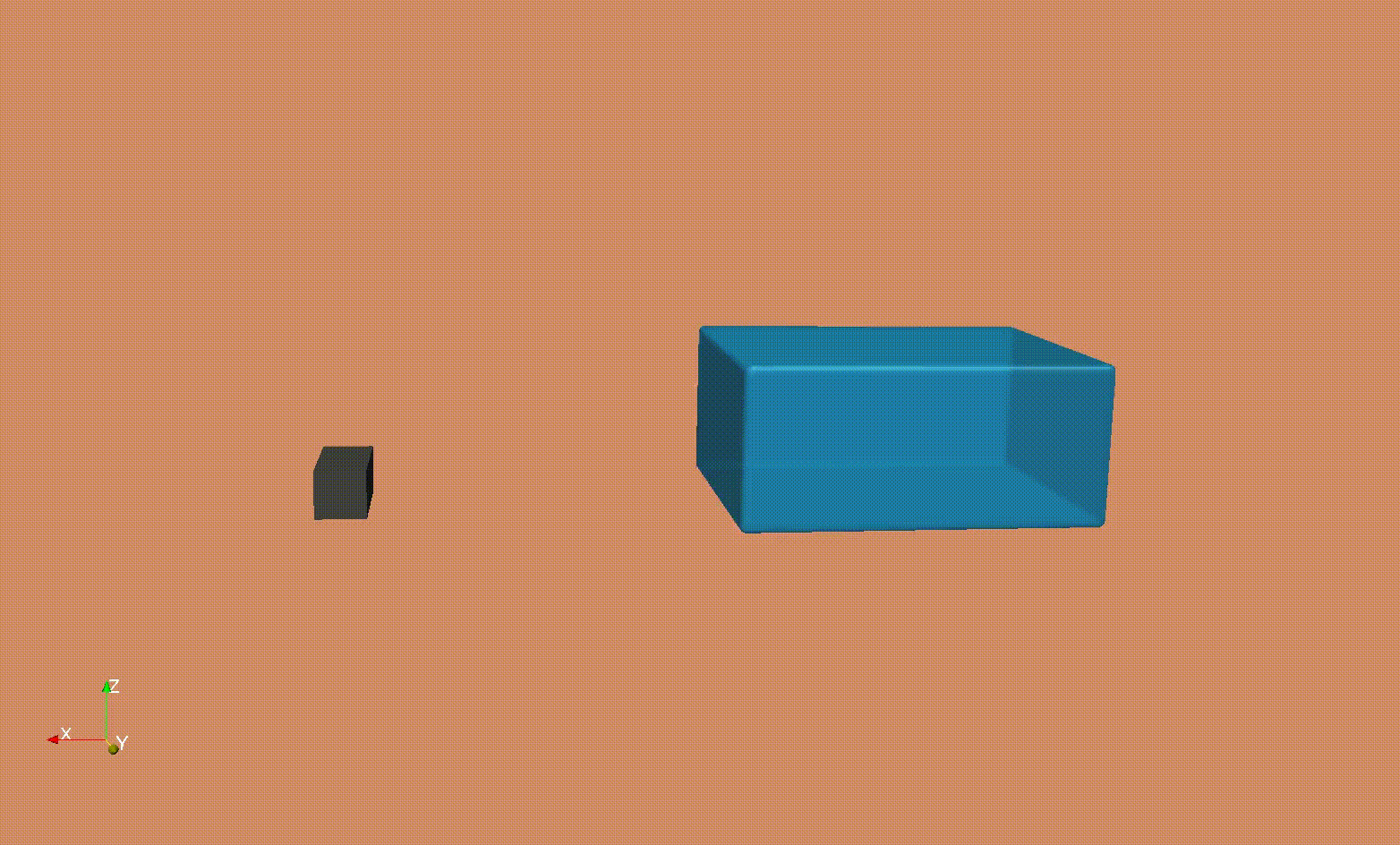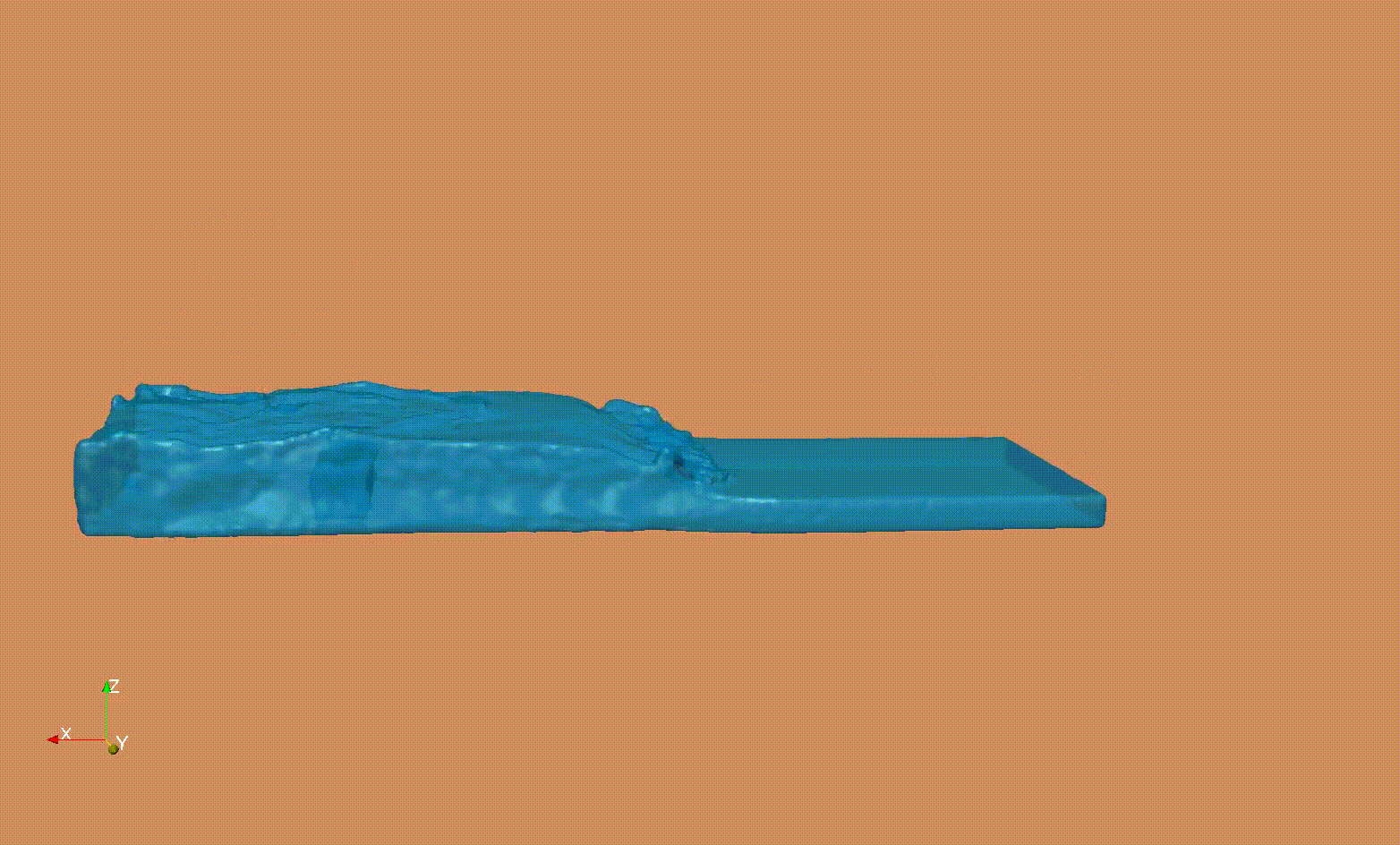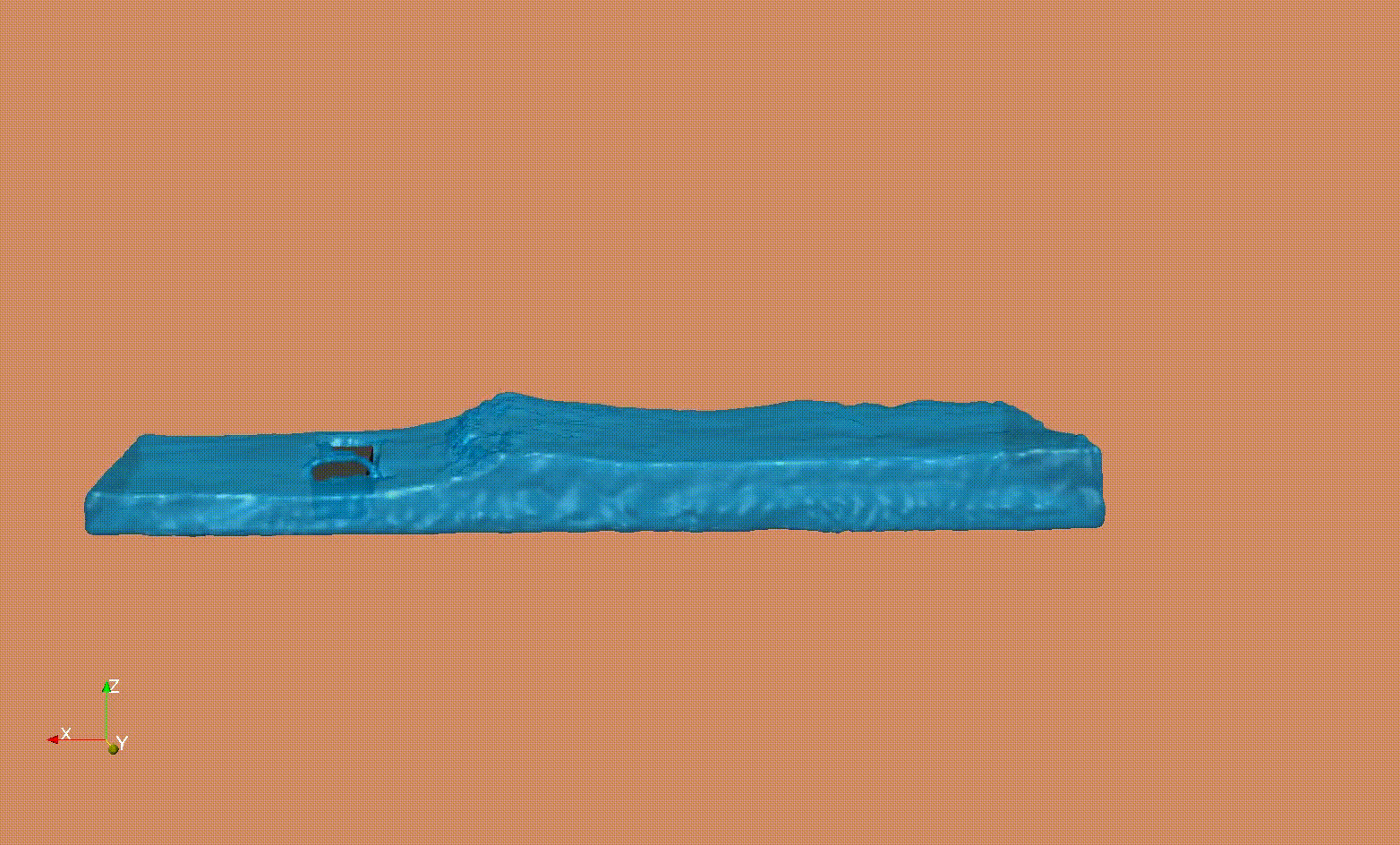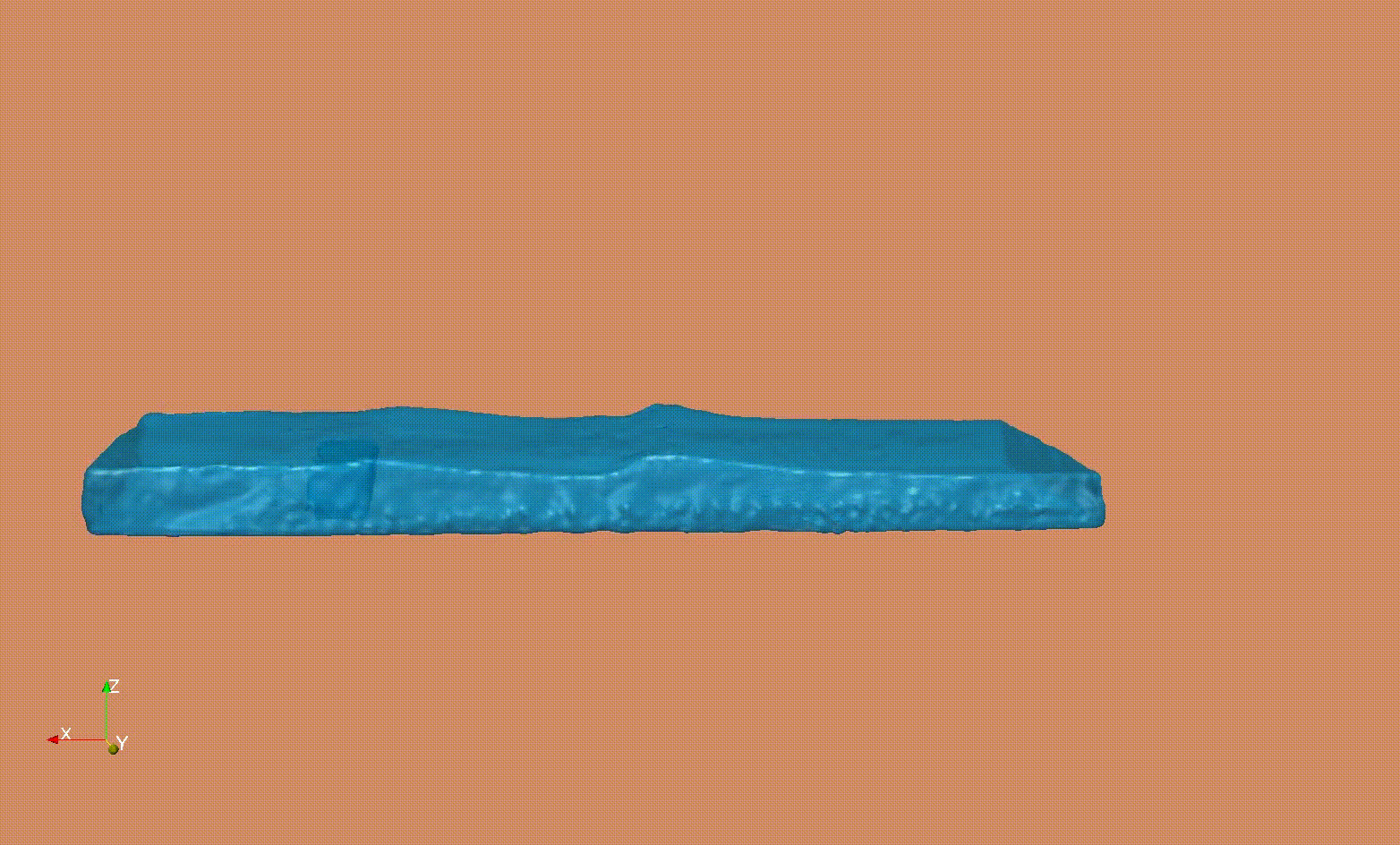
SPH simulation of a dam break - Verification, Validation and Parameters studies
Master project
Report
Smooth Particle Hydrodynamics (SPH) to investigate the impact of tsunami-like waves loads on dam structures.
Miscellaneous
LaReL 2022 NeurIPS Workshop: Language and Reinforcement Learning
Twitter
Co-organized the in-person workshop.
Promotional video capsule: Ubisoft La Forge - SWARM
Assisted designers with the Machine Learning vulgarization content.
Resources
I'll keep on adding here some resources that might be useful to some.